Introducción
Para este trabajo vamos a estar utilizando datos sobre libros en Goodreads y sus notas, estos se pueden sacar de aquí. También utilizaremos datos sobre el número de hablantes de cada idioma que se pueden encontrar aquí
Los datos se pueden cargar en la memoria de de R/RStudio de esta forma:
Y descargamos la biblioteca:
¿Qué libros le gusta a la gente?
Empezaremos con un gráfico de burbujas para observar qué libros han tenido más éxito, obteniendo mayores notas medias.
Código
burbujas <- goodreads %>%
mutate (anio = str_extract(publication_date, "\\d{4}$")) %>%
drop_na () %>%
arrange (desc(average_rating)) %>%
filter (average_rating >= 4.65)
p <- burbujas %>%
mutate (language_code = factor(language_code, levels = unique(language_code))) %>%
mutate (text = paste("Libro: ", title,
"\nIdioma: ", language_code,
"\nNota: ", average_rating,
"\nAño: ", anio,
"\nNúmero de votos: ",
ratings_count, sep="")) %>%
ggplot (aes(x = anio, y = average_rating, size = ratings_count, color = language_code, text=text)) +
geom_point (alpha = 0.7) +
scale_size (range = c(1.4, 19), name = "Nº votos") +
scale_color_viridis (discrete = TRUE, guide = FALSE) +
theme_ipsum () +
theme (legend.position = "none") +
labs (title = "Libros con mejor media",
x = "Año", y = "Nota media")
pp <- ggplotly (p, tooltip="text")
ppCodigo inspirado en este.
Como se puede observar, muchos libros con una puntuación de 5 sobre 5 tienen muy pocas reviews, por lo que vamos a descartarlos y poner un mínimo de 10.000 reviews para elaborar un top 10 más preciso. También eliminaremos las sagas para centrarnos únicamente en libros individuales.
Código
top_libros <- goodreads %>%
filter (ratings_count >= 10000) %>%
filter (!str_detect(title, regex("\\bset\\b", ignore_case = TRUE))) %>%
filter (!str_detect(title, regex("\\bcollection\\b", ignore_case = TRUE))) %>%
select (title, authors, average_rating) %>%
arrange (desc(average_rating)) %>%
head(10)
DT::datatable(top_libros)Podemos observar que la saga “Calvin and Hobbes” de Bill Watterson tiene un gran éxito en Goodreads y que la mayoría de libros en el top son cómics o mangas. Además, aparecen sagas muy conocidas como “Harry Potter” y “El señor de los anillos”.
¿Quién debería escribir nuestro libro?
Para continuar formando el mejor libro, vamos a ver qué autores tienen mejor nota media filtrando también con más de 10.000 reviews y que sean libros individuales.
Código
top_autores <- goodreads %>%
filter (ratings_count >= 10000) %>%
filter (!str_detect(title, regex("\\bset\\b", ignore_case = TRUE))) %>%
filter (!str_detect(title, regex("\\bcollection\\b", ignore_case = TRUE))) %>%
group_by (authors) %>%
summarise (nota_media = weighted.mean(average_rating, w = ratings_count)) %>%
arrange (desc(nota_media)) %>%
head (10) %>%
mutate (autores = str_trunc(authors, 20)) %>%
ungroup ()
p2 <- ggplot (top_autores, aes(x = nota_media, y = reorder(autores, nota_media))) +
geom_col (fill = "#7831a2") +
coord_cartesian (xlim = c(4, 5)) +
labs (title = "Autores con mejor media",
x = "Nota media", y = "Autores")
p2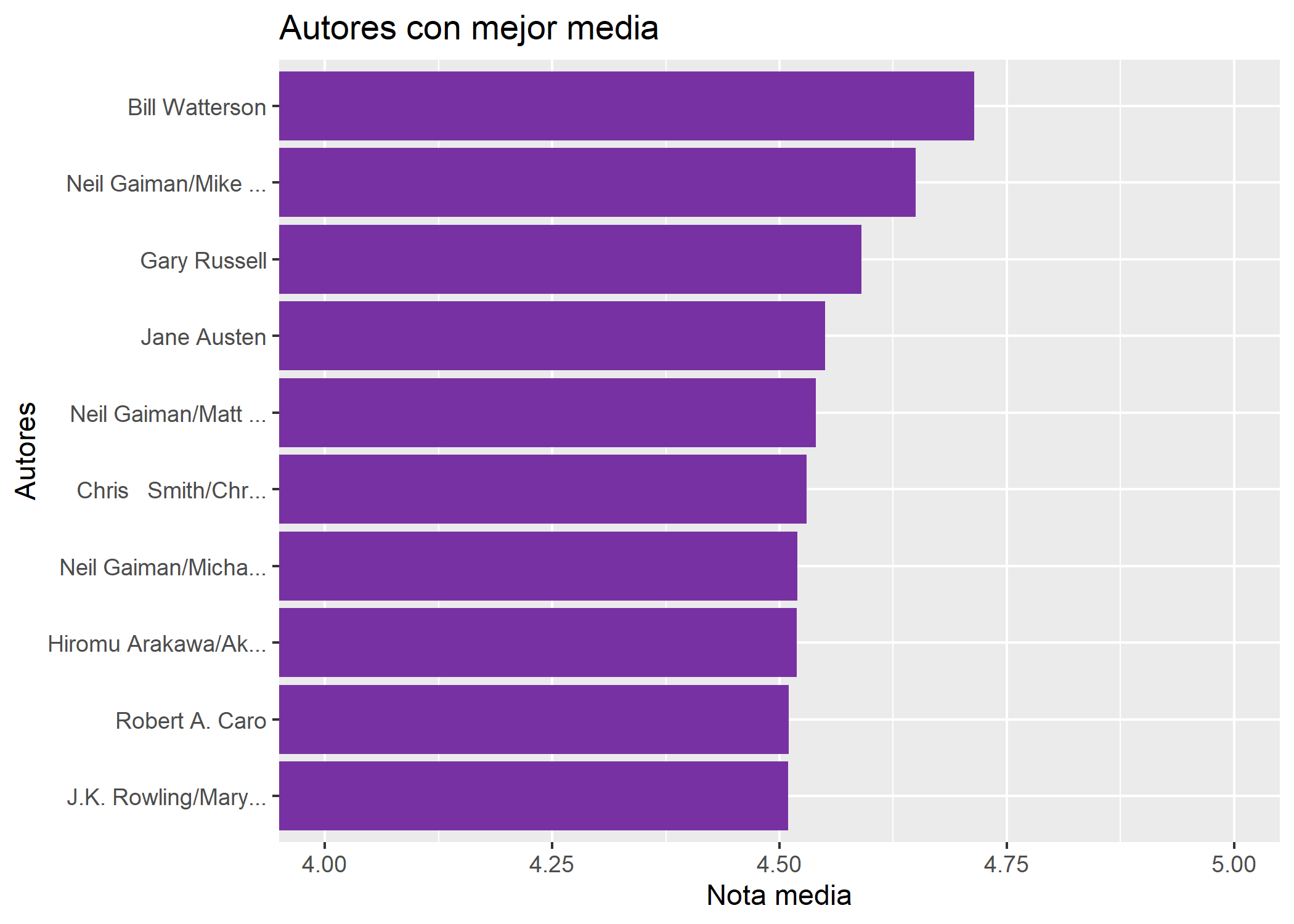
Se puede observar, como se esperaba al ver el top 10 de libros, que el autor con mejor nota media es Bill Watterson. Aunque también podemos ver a Neil Gaiman en tres posiciones diferentes del top, al tratarse de él junto a muchos otros autores, preferimos quedarnos con B. Watterson para que se trate únicamente de un autor.
¿Cuántas páginas debe tener nuestro libro?
Ahora, vamos a ver cómo de largo tiene que ser nuestro libro basándonos en las reviews de la gente.
Código
p3 <- goodreads %>%
mutate (rang_pag = round(num_pages / 25) * 25) %>%
group_by (rang_pag) %>%
summarise (notita = weighted.mean(average_rating, w = ratings_count)) %>%
ggplot (aes(x = rang_pag, y = notita)) +
geom_area (fill = "#7831a2") +
coord_cartesian (xlim = c(0, 1500), ylim = c(3, 5)) +
labs (title = "Nota media por cada 50 páginas",
x = "Número de páginas", y = "Nota Media")
p3
Codigo inspirado de aquí.
Podemos ver que el rango de mejores reviews está entorno a las 1.300 páginas por lo que nuestro libro tendrá que situarse en ese rango.
¿En qué idioma debería estar nuestro libro?
Por último, queremos echar un vistazo a qué idiomas reciben mejores reviews para decidir en qué idioma debería escribirse nuestro libro para que sea el mejor. Para ello, realizaremos un gráfico de violín unificando todos los diferentes códigos de inglés para que cuenten como uno solo y filtrando los diez idiomas con mejor nota media.
Código
top_idioma <- goodreads %>%
mutate (language_code = fct_collapse(language_code,
"eng" = c("eng", "en-GB", "en-US", "en-CA", "enm"))) %>%
group_by (language_code) %>%
summarise (media = weighted.mean(average_rating, w = ratings_count)) %>%
arrange (desc(media)) %>%
head (10) %>%
pull(language_code)
p4 <- goodreads %>%
mutate (language_code = fct_collapse(language_code,
"eng" = c("eng", "en-GB", "en-US", "en-CA", "enm"))) %>%
filter (language_code %in% top_idioma) %>%
ggplot (aes(x = reorder(language_code, -average_rating), y = average_rating)) +
geom_violin (fill = "#7831a2") +
coord_cartesian (ylim = c(3, 5)) +
labs (title = "Nota media por idiomas",
x = "Idioma", y = "Nota Media")
p4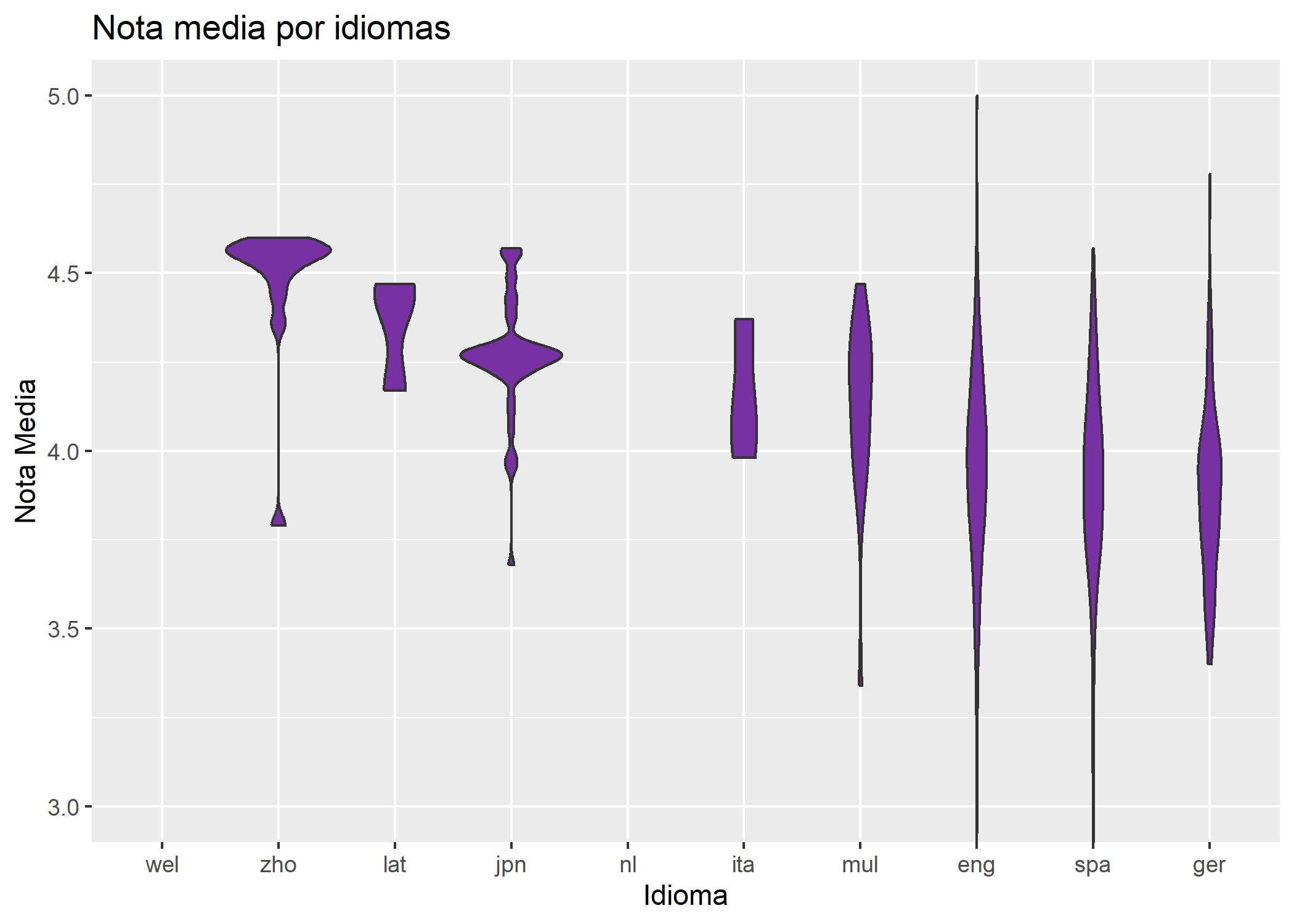
Codigo inspirado de aquí.
Se puede observar que el idioma con mejor nota media es el chino. Sin embargo, para comprobar si realmente este idioma tiene tantos lectores potenciales, analizaremos cuáles son los idiomas más hablados.
Código
Este gráfico nos muestra que el chino es el segundo idioma más hablado, con muy poca diferencia respecto al primer puesto, que corresponde al inglés. Por lo tanto, escribiendo el libro en chino sí podríamos llegar a una audiencia muy amplia.
De esta manera, ¡¡hemos conseguido definir cómo debería ser el mejor libro del mundo!! Este debería ser un cómic o manga escrito por Bill Watterson, en chino, y de unas 1.300 páginas.
¡Y hasta aquí mi trabajo de Big Data, espero que os haya gustado!
